
Articoli
A prova di bomba: OpenBSD

Meglio di Linux per la sicurezza esiste solo OpenBSD
Per essere veramente a prova di bomba un computer deve avere due requisiti: un hardware “pulito”, cioè privo di chip spioni (perché se la cimice è a livello hardware, non c’è niente da fare), e un sistema operativo con gli attributi giusti. Nel mondo degli esperti di sicurezza le distribuzioni GNU/Linux più aggressive e meglio configurate permettono di raggiungere livelli di impenetrabilità che Windows e macOS si sognano.
C’è però un sistema operativo ancora più sicuro, soprattutto quando si impara a pilotarlo a modo: OpenBSD. Niente a che vedere con Ubuntu o simili distro vanilla, dimentichiamo le “install fest” con nuove funzionalità ogni tre mesi. OpenBSD è stabile, sicuro, ogni riga di codice è stata testata quattro volte da gruppi diversi di esperti e la documentazione è la migliore che si possa trovare su qualsiasi sistema operativo.
Una sola comunità
Nel numero 226 di Hacker Journal abbiamo già parlato di UNIX e dei suoi eredi, le Berkeley Software Distribution dell’Università della California, cioè BSD.
A differenza di Linux, che mette assieme un kernel con una serie di strati software eterogenei, le release BSD vengono sviluppate organicamente dalla stessa comunità. Questo permette una maggiore integrazione e un approccio molto più centrato sulla filosofia stessa della distribuzione. Oggi OpenBSD è la scelta di riferimento per firewall, server Web, mail server, fa parte del pacchetto di codice scelto da Microsoft per le estensioni UNIX di Windows 10.
OpenBSD è minimale, non ha una modalità d’installazione a pacchetti semplificata: ci vogliono dieci minuti per installarlo ma bisogna sapere cosa si sta facendo. Infatti OpenBSD richiede che l’utente sappia già tutto e decida passo per passo cosa fare soprattutto nell’ambito della sicurezza.
Perché installarlo
Se abbiamo già configurato un sistema come firewall, un gateway per VPN o IDS (Intrusion Detection System), abbiamo lavorato quasi sicuramente con OpenBSD. E questo è un ottimo motivo per pensare di installarlo sulla nostra macchina e farne uno dei propri sistemi operativi di riferimento, se non il principale.
Ci sono vari scenari di utilizzo di OpenBSD. Se vuoi scoprirli nel dettaglio corri in edicola e acquista Hacker Journal 228 oppure clicca qui.

Articoli
I gadget segreti degli hacker
La valigetta del pirata contiene dispositivi hi-tech piccoli, anonimi e potenti, facilmente acquistabili anche su Amazon. Ecco la nostra selezione

CASTELL DECO
BEN NASCOSTI SI’, MA IN UN VASO!
La cassaforte mimetizzata CASTELL DECO è un innovativo contenitore di sicurezza, camuffato da fioriera per uso interno ed esterno. Ideale per nascondere denaro, carte di credito e documenti, presenta un design intelligente. Realizzata con materiali robusti, include un contenitore in metallo con strato inferiore in acciaio e superiore in ABS, antiruggine e resistente alle intemperie. La serratura a chiave, con due chiavi incluse, garantisce sicurezza, mentre i fori preinstallati permettono un fissaggio stabile. Dimensioni compatte per una mimetizzazione discreta e efficace.
Quanto costa: € 26,97
Dove acquistarlo: su Amazon

EKNA
COSA SI CELA DIETRO IL TEMPO?
Si tratta di una cassaforte segreta, camuffata da orologio da parete, ideale per proteggere denaro, medicine, carte di credito, documenti, chiavi, gioielli e altri oggetti di valore. Realizzata con materiali robusti, offre una protezione indistruttibile e discreta. Il design autentico, con bevande e lattine originali dal mercato europeo, crea un’illusione perfetta per la protezione antifurto. Installabile come un normale orologio, si apre come una porta rivelando il vano segreto. La confezione include un orologio originale con scomparto nascosto, rendendolo anche un’idea regalo unica e funzionale.
Quanto costa: € 22,50
Dove acquistarlo: su Amazon

CORNICE PER FOTO
IN FOTO C’È MOLTO DI PIÙ
Questa cornice foto SKS rappresenta un avanzato nascondiglio segreto per denaro e oggetti di valore. Realizzata in legno di pino di alta qualità, garantisce robustezza e versatilità. La cornice, dotata di vetro liscio e resistente, include una borsa ignifuga e impermeabile, capace di proteggere i beni fino a 10 minuti di esposizione al fuoco diretto. Le dimensioni esterne sono 25 x 20 x 4,3 cm, mentre lo spazio interno misura 22 x 17 x 1,5 cm, perfetto per conservare documenti e gioielli. Utilizzabile come porta foto da tavolo o da parete, garantisce sicurezza discreta in piena vista
Quanto costa: € 24,00
Dove acquistarlo: su Amazon

Leggi anche: ” Scopri altri gadget segreti dell’hacker”
Articoli
Energia sotto attacco hacker
Uno degli ultimi malware intercettati durante il cyberconflitto Russia-Ucraina ha colpito il settore energetico

Di recente, il malware Industroyer2 si è distinto come una delle armi più pericolose impiegate nella guerra in Ucraina. Conosciuto anche come CrashOverride, si tratta di un agente altamente sofisticato che mira a compromettere i sistemi di automazione industriale (ICS), utilizzati ampiamente nel settore energetico. È in grado di infiltrarsi nei sistemi SCADA (Supervisory Control And Data Acquisition) e di compromettere le infrastrutture critiche, come le sottostazioni elettriche e le reti di distribuzione. Sfrutta vulnerabilità presenti nei protocolli di comunicazione utilizzati nei sistemi ICS, tra cui il protocollo IEC 61850, comunemente impiegato nel settore energetico. Attraverso l’analisi delle reti e l’intercettazione dei comandi di controllo, è in grado di eseguire attacchi mirati e causare il blackout delle reti elettriche.
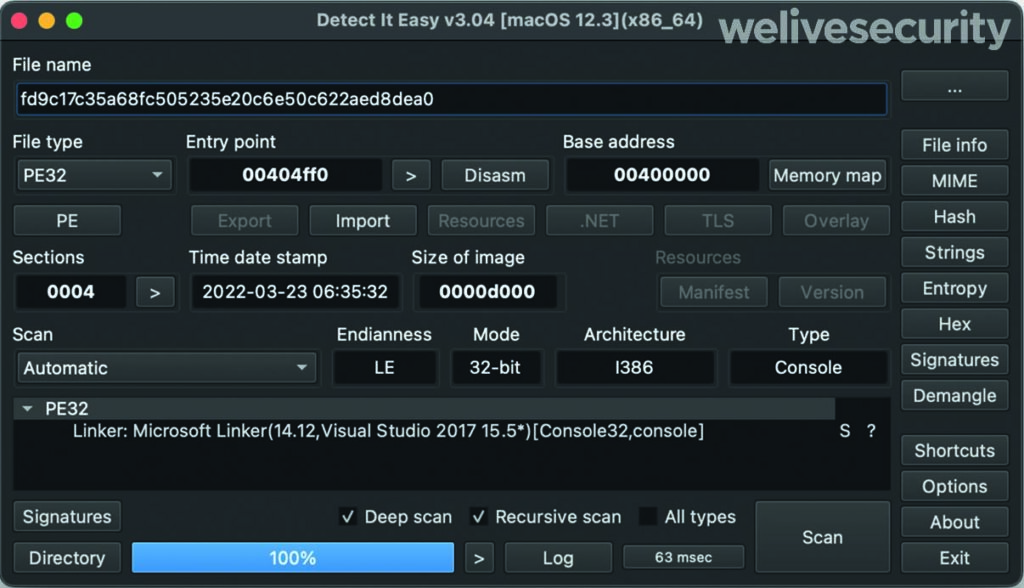
Industroyer2 implementa solo il protocollo IEC-104 (noto anche come IEC 60870-5-104) per comunicare con le apparecchiature industriali. Fonte: https://www.welivesecurity.com
MODALITÀ DI ATTACCO
Industroyer2 si diffonde attraverso varie fasi di attacco, ognuna delle quali svolge un ruolo specifico nel compromettere l’infrastruttura target. Tra le sue funzionalità principali, possiamo identificare: il rilevamento della rete, l’analisi della rete e l’identificazione dei dispositivi, nonché l’individuazione di vulnerabilità presenti. Subito dopo, tenta di creare delle interferenze con i protocolli di comunicazione: il malware manipola i messaggi di controllo inviati tra le diverse componenti del sistema ICS. Ciò gli consente di assumere il controllo dei dispositivi e di modificare il loro comportamento. Infine, disabilita i dispositivi critici come interruttori, trasformatori e generatori, provocando un black-out e danni significativi alle infrastrutture.
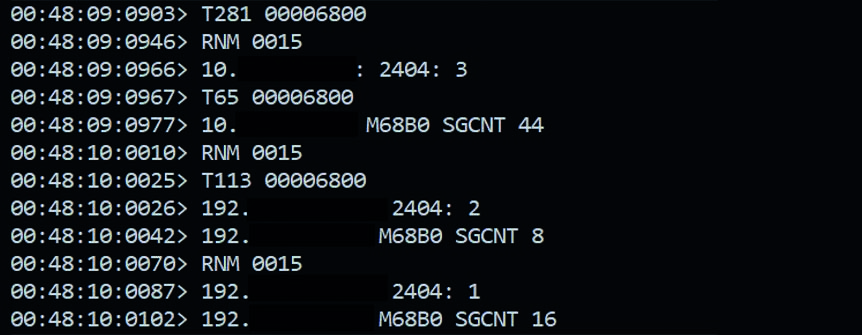
Una volta avviato Industroyer2, si apre una finestra del prompt che visualizza i comandi che vengono inviati e ricevuti. In questo caso, a essere presa di mira è la porta 2404 utilizzata da IEC-104 per inviare messaggi TCP. Fonte: https://www.sentinelone.com
PAROLA D’ORDINE: COLLABORAZIONE
Durante gli attacchi ai sistemi energetici hanno causato black-out prolungati, con conseguente mancanza di elettricità per le comunità colpite. Questo ha avuto un impatto diretto sulle attività quotidiane, inclusi i servizi essenziali come l’approvvigionamento idrico, i trasporti e i servizi sanitari. Tanto che Industroyer2 ha spinto la comunità internazionale a intensificare gli sforzi per la prevenzione e la mitigazione delle minacce cibernetiche nel settore energetico. Le agenzie governative, i ricercatori di sicurezza informatica e le aziende del settore energetico stanno collaborando per sviluppare contromisure e soluzioni di difesa più efficaci.
NUOVA VERSIONE
In concomitanza con la diffusione di Industroyer2 nella rete ICS, gli attaccanti hanno distribuito anche una nuova versione del malware CaddyWiper, molto probabilmente con lo scopo di rallentare il processo di recupero e impedire agli operatori della compagnia energetica di riprendere il controllo delle console ICS. È stato anche distribuito sulla macchina in cui è stato eseguito Industroyer2, probabilmente per coprire le loro tracce.
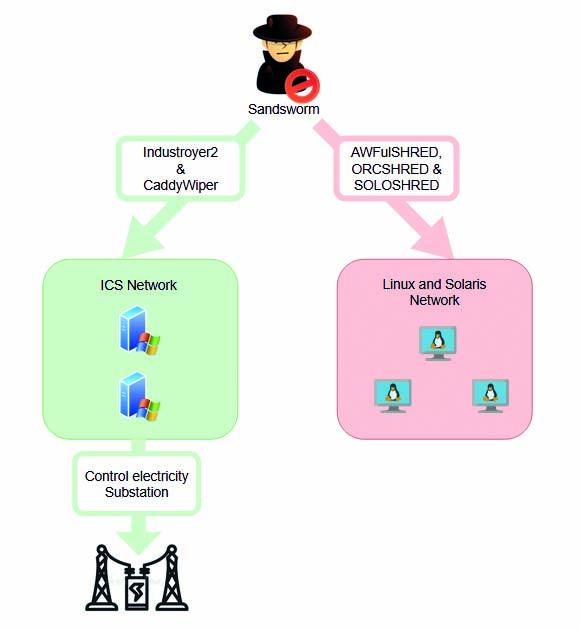
Schema di funzionamento dell’attacco combinato di Industroyer2 e CaddyWiper. Fonte: https://www.headmind.com/fr/industroyer-2/
Articoli
Misura le prestazioni del PC
I sistemi per monitorare le performance del sistema e sfruttare al massimo le sue potenzialità
Anni fa la prima cosa che faceva un appassionato di computer non appena cambiava una componente o acquistava un nuovo PC era far girare i cosiddetti benchmark, programmi creati per valutare le prestazioni di un computer. I più utilizzati erano i benchmark integrati all’interno dei motori di gioco (come Quake e Unreal), che servivano anche a capire se il computer fosse in grado di eseguire quello specifico titolo alla risoluzione scelta a una velocità accettabile.
PERCHÉ FARE UN TEST?
I programmi per effettuare benchmark sul computer fondamentalmente indicano la sua velocità tramite un numero. Più questo numero è elevato, maggiori sono le prestazioni. Questo valore, però, di per sé ha poco significato se non lo si paragona ad altre configurazioni, così da comprendere se la macchina è più veloce o più lenta di un’altra. Questo può tornarvi molto utile anche per capire l’impatto di una variazione nella configurazione del PC. Quanto cambia il valore se aumentate la RAM? E se sostituite il processore? Quanto è più veloce la nuova scheda grafica di quella precedente? I nuovi driver sono più efficienti o rallentano il PC rispetto a quelli precedenti? Questo programma gira meglio su CPU Intel o sui chip di Apple?
UNO DEI MIGLIORI
Tra i più noti, e meno complessi, programmi per la misurazione delle prestazioni dei computer (e non solo) troviamo Geekbench. Per dare un senso al punteggio, tenete conto del fatto che il software è calibrato attorno a un computer Dell Precision 3460 con processore Intel Core i7- 12700. Questa configurazione ottiene un punteggio base di 2.500. Geekbench effettua una serie di test. Il valore che vi interessa di più è quello Multi- Core, che misura le prestazioni dell’intero sistema. Il valore Single Core vi interessa relativamente, dato che la maggior parte delle applicazioni moderne sfrutta tutti i core presenti sul processore. Il test della GPU, invece, si limita a valutare le capacità di calcolo della scheda video, in ambito ludico e non solo. Potete scegliere fra due API: OpenCL e Vulkan. La prima è la più utilizzata in ambito Windows. Vulkan, invece, è meno diffusa ma sulla carta è in grado di offrire prestazioni migliori. A seguire eseguiamo entrambi i test.
DOWNLOAD
Collegatevi sul sito www.geekbench.com, cliccate su Download e scaricate la versione del programma per il vostro sistema operativo. Al termine del download fate doppio clic sul file .exe e procedete con l’installazione.
SERVE INTERNET
Avviate il programma: vi verrà presentata una schermata che riassume le caratteristiche del PC (processore, RAM e via dicendo). Chiudete tutti i programmi prima di eseguire il benchmark. Serve una connessione Internet attiva.
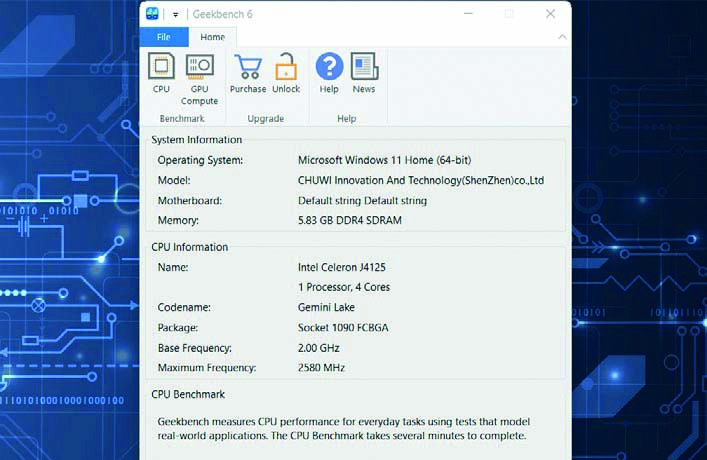
AVVIATE I TEST
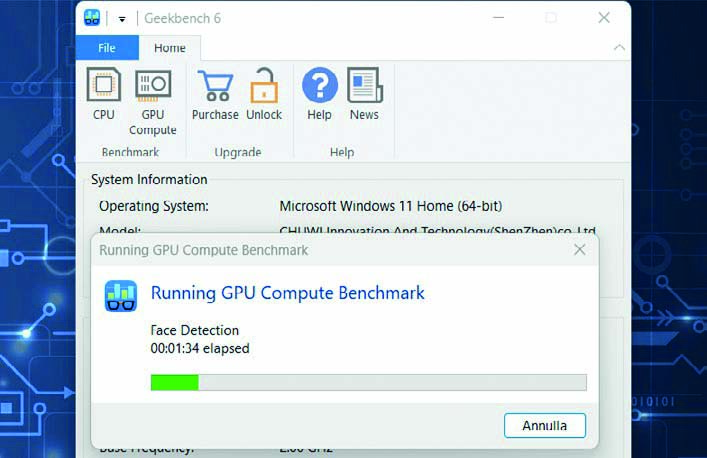
Dopo aver chiuso tutte le applicazioni, potete cliccare su Run CPU Benchmark. Una volta fatto, prendetevi qualche minuto di pausa e non toccate il computer mentre vengono eseguiti i test.
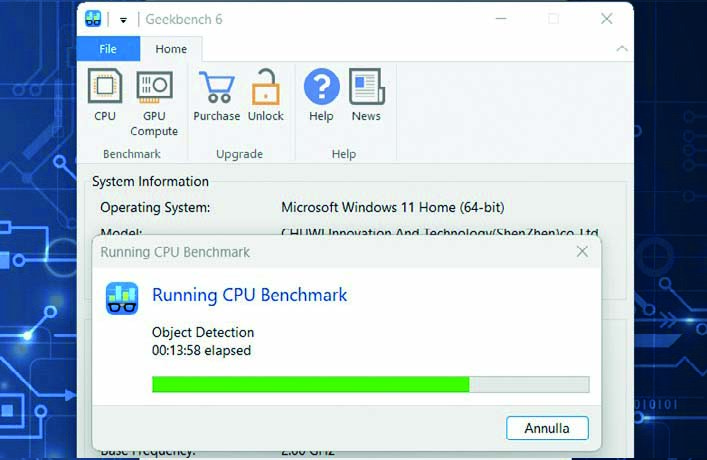
REGISTRAZIONE?
Terminato il benchmark si aprirà una finestra del browser con il risultato numerico che indicherà le “prestazioni” del vostro PC. Se premete il pulsante Sign up potrete registrarvi sul sito di Geekbench e…
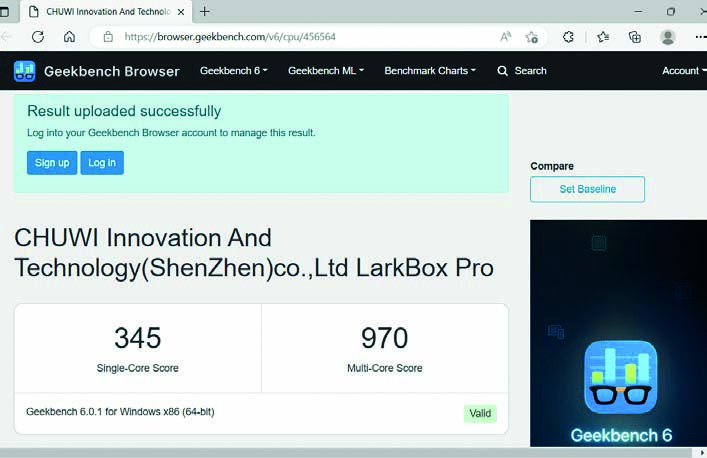
CONTROLLATE I VALORI
…salvare i vostri risultati online, confrontandoli con quelli di configurazioni simili, pubblicate da altri utenti. Se avete dei valori molto più bassi di un PC simile, valutate di aggiornare i driver, quantomeno.
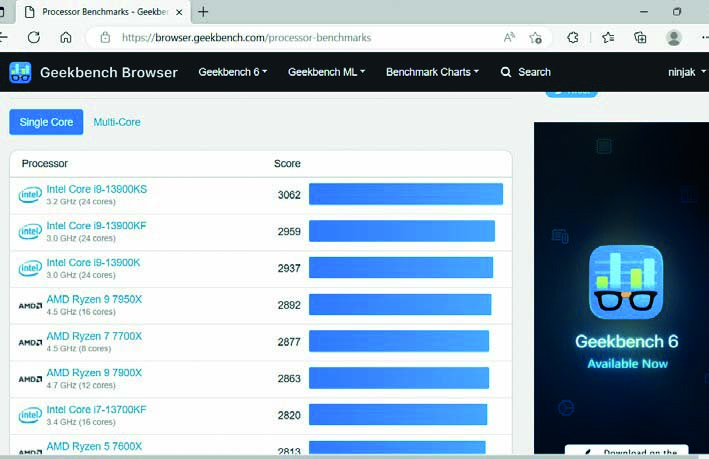
TESTATE LA POTENZA DELLA SCHEDA VIDEO
Tornate su Geekbench e premete in alto il pulsante GPU Compute per testare la potenza della scheda video. Al termine, ritroverete online anche questo valore, da confrontare con altre configurazioni simili.
Leggi anche: “Tracciamo l’attività del PC”
*illustrazione articolo progettata da Freepik
Articoli
Una nuova genia di rivoluzionari
Gli hacker sono descritti da Stewart Brand come la “fetta di intellettuali più interessante ed efficiente dall’epoca della stesura della Costituzione degli Stati Uniti”.

Prima di addentrarci nell’universo degli hacker e del loro impatto culturale e sociale, è essenziale comprendere la figura di Stewart Brand, l’uomo che sta dietro il concetto riportato nel sottotitolo di questo articolo. Nato nel 1938, Brand è una figura poliedrica: editore, autore e visionario, il suo nome è indissolubilmente legato alla pubblicazione del Whole Earth Catalog, una rivista che negli anni ‘60 e ‘70 forniva accesso a strumenti e idee per la comunità della controcultura, promuovendo un approccio fai-da-te alla vita e alla tecnologia.
LA VITA
Dopo aver studiato biologia alla Stanford University, Brand si è immerso nella controcultura della California, diventando un sostenitore delle comunità alternative e dell’uso di sostanze psichedeliche come strumenti per l’esplorazione della mente. Il suo incontro con i membri della comunità informatica di Silicon Valley lo ha portato a riconoscere presto il potenziale rivoluzionario dei computer, non solo come strumenti di calcolo, ma come mezzi per espandere la creatività umana e la condivisione della conoscenza.
CUSTODI DELL’EFFICIENZA E DELL’INNOVAZIONE
Nel contesto delineato da Brand, gli hacker non sono semplici appassionati di tecnologia o esperti informatici. Sono, piuttosto, eredi della filosofia illuminista, propugnatori di un sapere aperto e condiviso, impegnati nella costante ricerca dell’efficienza, dell’innovazione e dell’ottimizzazione. Brand li vede come figure chiave nella transizione verso nuove forme di società, basate sulla conoscenza e sull’accesso democratico all’informazione.
Secondo l’editore gli hacker incarnano un ethos basato sulla meritocrazia, sull’autonomia e sulla libertà di esplorazione intellettuale. Questi principi, che risuonano profondamente con lo spirito della Costituzione degli Stati Uniti, trovano nella tecnologia digitale il loro terreno di coltura ideale. Gli hacker, con la loro capacità di manipolare e “hackerare” i sistemi esistenti per migliorarli o crearne di nuovi, rappresentano una forza propulsiva per l’innovazione e il progresso.

Stewart Brand ha fatto parte del gruppo di futurologi che hanno collaborato alla preparazione della pellicola Minority Report, film del 2002 diretto da Steven Spielberg e tratto dall’omonimo racconto di fantascienza di Philip K. Dick. Foto: Joi Ito from Inbamura, Japan – Licenza: CC BY 2.0.
L’ETICA HACKER E IL FUTURO DELLA SOCIETÀ
L’influenza degli hacker si estende ben oltre il mero ambito tecnologico. La loro etica, basata sulla trasparenza, sul lavoro collaborativo e sulla libertà di accesso all’informazione, ha il potenziale di trasformare anche i sistemi sociali, economici e politici. Brand sottolinea come l’adozione di questi principi possa portare a una società più aperta, equa e resiliente, in cui l’informazione diventa un bene comune, accessibile a tutti.
Questo cambiamento non è privo di sfide. La tensione tra la tutela della privacy individuale e la condivisione libera dell’informazione, il rischio di polarizzazione e l’uso distorto delle tecnologie digitali sono solo alcuni dei problemi che la società deve affrontare. Tuttavia, secondo Brand, la chiave per superare questi ostacoli risiede proprio nell’approccio hacker: un’impostazione mentale che privilegia la soluzione creativa dei problemi, l’adattabilità e l’ottimismo tecnologico.
L’EREDITÀ DEGLI HACKER
La visione di Stewart Brand sugli hacker come nuovi intellettuali rivoluzionari va intesa come un invito a riconsiderare il ruolo della tecnologia e della conoscenza nella società contemporanea. Brand stesso, con la sua vita e le sue opere, incarna questa visione, avendo contribuito a plasmare alcuni dei movimenti più influenti del nostro tempo, dalla controcultura alla nascita della cultura digitale.
La sua fiducia nel potenziale umano, nella capacità di usare la tecnologia per migliorare la condizione umana, è un messaggio di speranza e di sfida. Gli hacker, nella loro incessante ricerca di soluzioni innovative, ci ricordano che il futuro è nelle nostre mani, pronto a essere “hackerato” e riscritto per il bene comune.
In conclusione, la descrizione di Stewart Brand degli hacker come intellettuali tra i più interessanti ed efficienti dal 1787 non è solo un omaggio alla loro ingegnosità tecnica. È un riconoscimento del loro ruolo cruciale come motori di cambiamento sociale e culturale, eredi di una tradizione di pensiero critico e innovazione che ha le sue radici nella stessa fondazione degli Stati Uniti. In questo senso, gli hacker non sono solo esperti informatici, ma custodi di un ethos che potrebbe guidare l’umanità verso orizzonti ancora inesplorati.


Il Whole Earth Catalog fu un’iniziativa editoriale concepita da Brand, mirata a divulgare prodotti utili per chiunque desiderasse plasmare il proprio spazio vitale e condividerne il processo. Fu attiva tra il 1968 e il 1971.
Leggi anche: “L’IA al servizio degli hacker”
Articoli
A tutta musica con Linux
Giada è uno strumento di produzione musicale versatile e robusto, destinato principalmente a DJ, artisti che si esibiscono dal vivo e autori di musica elettronica.
Di base, il software funziona come una loop machine, consentendovi di costruire performance in tempo reale stratificando tracce audio o eventi MIDI, il tutto orchestrato dal suo sequencer principale. Giada è anche un lettore di campioni completo e, se vi dedicate alla scrittura di canzoni o desiderate modificare registrazioni dal vivo, il suo potente Action Editor offre un controllo preciso per creare o modificare i pezzi con precisione. Le capacità di registrazione di Giada non si limitano alle sorgenti digitali: può anche catturare suoni dal mondo reale ed eventi MIDI da dispositivi esterni o altre applicazioni. Funziona inoltre come processore di effetti, offrendovi la libertà di elaborare campioni o segnali di ingresso audio/MIDI con gli strumenti VST della vostra libreria di plug-in.
L’ultima versione ha introdotto miglioramenti nell’usabilità e nella funzionalità di varie caratteristiche
Giada si distingue anche come controller MIDI, consentendo il controllo di altri software o la sincronizzazione di dispositivi MIDI fisici se lo usate come master sequencer MIDI. Il suo design si concentra sulle esigenze delle performance dal vivo, con un potente motore audio multi-thread, un’interfaccia elegante e priva di inutili complessità e il supporto per VST3, LV2 e I/O MIDI. È uno strumento leggero ma potente, che riesce a soddisfare l’ambiente esigente delle esibizioni live. Supporta un’ampia gamma di sistemi operativi tra cui, oltre a Linux, Windows, macOS e FreeBSD, il che lo rende utilizzabile in un’ampia varietà di situazioni. L’ultima versione, la 1.0.0 “Genius loci”, introduce diverse novità, come un menu principale ridisegnato, indicatori audio verticali nella finestra di I/O e miglioramenti nell’usabilità e nella funzionalità di varie caratteristiche. L’applicazione è al 100% Open Source con licenza GPL, quindi potete intervenire sul suo codice se avete esigenze specifiche. Può essere scaricata da qui. mentre a questo indirizzo trovate una guida dettagliata sul suo utilizzo.

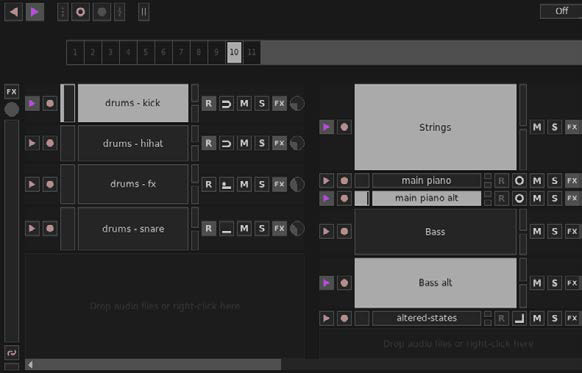
1- Controlli di trasporto
Controlla il sequencer e comprende il pulsante play/stop e il pulsante rewind che riporta rapidamente alla prima battuta.
2- Sequencer
Mantiene la sincronizzazione della performance dal vivo ed è responsabile della gestione di loop, campioni ed eventi MIDI.
3- Colonne e canali
Le colonne sono usate per organizzare il progetto e disporre i canali, che a loro volta contengono campioni audio o eventi MIDI.
4- Ingresso principale
L’ingresso per l’I/O audio (l’uscita è a destra). Le manopole circolari controllano il volume e le barre verticali sono gli indicatori.
Leggi anche: “Tux N Mix: distro da scroprire“”
Articoli
Installiamo Ubuntu 24.04 LTS
A due anni esatti dalla precedente, Canonical ha rilasciato la nuova versione di Ubuntu supportata a lungo termine, o LTS, che è stata chiamata Noble Numbat, in onore di un marsupiale in via di estinzione. Gli aggiornamenti saranno disponibili fino al prossimo aprile 2029, garantendo a questo sistema operativo, tra i più diffusi in assoluto nell’universo Linux, il massimo della stabilità e dell’affidabilità

Rispetto alla precedente versione supportata a lungo termine, Jammy Jellyfish, Ubuntu 24.04 mette a disposizione degli utenti un programma di installazione completamente rinnovato. Non solo l’aspetto è più accattivante, ma anche l’intera procedura risulta essere più pratica e semplice delle precedenti, nel pieno rispetto della filosofia di Canonical di mettere sempre l’utente al centro delle proprie scelte. Per fare un esempio pratico, è stato implementato uno strumento che permette l’installazione automatica del sistema operativo, pur lasciandovi la facoltà di procedere nel modo più classico. È stato anche reintrodotto il supporto per l’installazione guidata del file system ZFS. Un’altra importantissima novità è la presenza del nuovo ambiente desktop basato su GNOME 46, il cui scopo principale è quello di migliorare l’esperienza utente. Anche il classico file manager Nautilus ha subito alcune migliorie, tra cui spicca il pulsante di ricerca, posizionato nella barra superiore, che ora permette di fare ricerche sia globali, sia locali. Per quanto riguarda le Impostazioni, c’è da notare che le voci sono state riorganizzate e che sono state aggiunte nuove opzioni per permettere una maggiore personalizzazione del sistema operativo. Per esempio, nella sezione Mouse e Touchpad è stato introdotto un interruttore che permette di impedire che il touchpad venga disabilitato per errore durante la digitazione.
L’interfaccia utente
Semplice, elegante e pratico, l’ambiente desktop che si presenta è quello tipico di Ubuntu, con il classico pannello dei preferiti sulla sinistra, chiamato dash, completamente personalizzabile. In alto a sinistra c’è il pulsante per visualizzare le aree di lavoro, mentre al centro della barra superiore si trovano il calendario e l’orologio. Il primo ha accesso diretto alla funzione eventi, che potete modificare a piacere, mentre il secondo permette l’aggiunta di altri fusi orari. A destra si trova il pulsante che permette di visualizzare un menu con varie opzioni, tra cui quella di attivare/disattivare lo Stile scuro e quella per attivare il risparmio energetico. Sempre da questo menu è possibile accedere con un clic alle Impostazioni. Per quanto riguarda la dotazione software, Ubuntu continua ad affidarsi ad applicazioni ormai consolidate come il pacchetto LibreOffice, Transmission e Rhythmbox, tanto per citarne alcune. Naturalmente non va dimenticato l’App Center, che permette di arricchire con un clic la già buona dotazione iniziale che il sistema operativo di Canonical mette a disposizione. La distro può essere scaricata da qui.
INSTALLAZIONE IN PRATICA!
Localizzazione
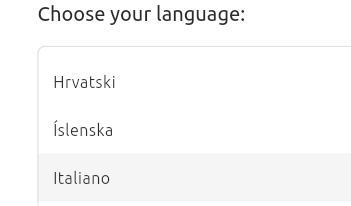
Nella prima schermata che vedete, lasciate selezionata l’opzione Try or Install Ubuntu e premete INVIO. In quella che segue, scorrete l’elenco delle lingue e fate clic su Italiano, che diventerà di colore rosso, e poi sul pulsante Next. Premete su Next in Accessibility in Ubuntu per saltare il passaggio.
Tastiera e collegamento di rete
In Scegliere la disposizione della tastiera, fate clic su Next, a meno che non abbiate bisogno di cambiarla, nel qual caso premete su Detect per farla riconoscere automaticamente. Nella schermata seguente, lasciate selezionata l’opzione predefinita, per esempio Usa connessione cablata, e fate clic su Next.

Scelta dell’installazione
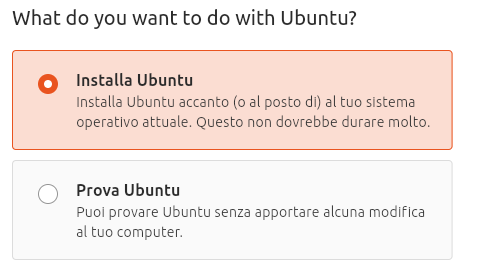
A questo punto potete scegliere se installare o provare Ubuntu. Qui si procederà con la sua installazione definitiva facendo clic su Installa Ubuntu. Quindi scegliete tra l’installazione interattiva e quella automatica. In questo caso si userà la prima, premendo su Interactive installation. Fate clic su Next.
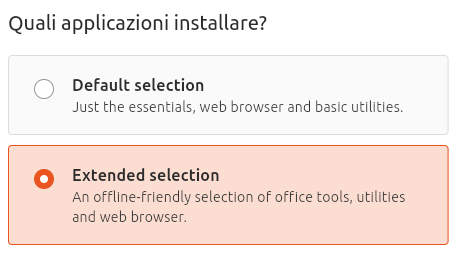
Scelta delle applicazioni
Nella schermata Quali applicazioni installare? potete scegliere tra la dotazione minima (Default selection) o quella completa (Extended selection). Sebbene sia possibile installare applicazioni anche successivamente, selezionate comunque la seconda opzione e fate clic su Next.
Software di terze parti e account
Ora selezionate le due opzioni della nuova schermata e fate clic su Next. Lasciate selezionato Cancella il disco e installa Ubuntu e premete su Next. Compilate il form con il nome utente e la password e, se volete, deselezionate Require my password to log in. Fate clic su Next e ancora su Next nella schermata che segue.

Installazione e primo avvio
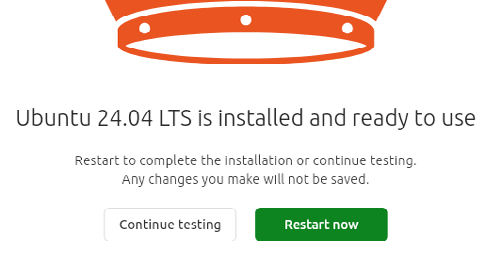
Fate clic su Installa e aspettate la fine della procedura. Al termine, premete su Restart now. Nella finestra di benvenuto, fate clic su Successiva. Lasciate selezionato Skip for now e premete ancora su Successiva. Decidete se condividere i dati di sistema e fate clic infine su Successiva, quindi premete su Termina.
Leggi anche: “Gestire spazio e RAM su Ubuntu“
Articoli
Mille distribuzioni a portata di mano
Strumento prezioso per gli sviluppatori che devono fare testing, è utile anche per gli amministratori di sistema e per chi ama spaziare nel mondo Linux
Nel variegato ecosistema di Linux, in cui la libertà di scegliere e personalizzare il proprio sistema operativo regna sovrana, Distrobox si distingue come una potente utility. Dà infatti agli utenti la possibilità di eseguire qualsiasi distribuzione all’interno di quella installata sfruttando la tecnologia dei container. Il processo di esplorazione, test o passaggio da un ambiente Linux all’altro risulta così semplificato e non avete la necessità di riavviare o modificare il sistema host. Nella sua essenza, Distrobox utilizza le solide capacità delle tecnologie di containerizzazione come Podman e Docker (dando anche accesso al più recente Lilipod) per creare ambienti Linux sul vostro sistema. Questo approccio offre un modo flessibile ed efficiente per gestire più distribuzioni o diverse versioni della stessa. Il fatto che, a differenza delle tradizionali configurazioni a doppio avvio o con macchine virtuali, Distrobox operi direttamente all’interno del vostro ambiente Linux principale risulta inoltre pratico e veloce.
Quando vi può essere utile
Distrobox brilla negli scenari che richiedono flessibilità e test in ambienti diversi. Per gli sviluppatori, offre una piattaforma preziosa per testare le applicazioni in diverse distribuzioni senza la necessità di configurazioni fisiche multiple, mentre gli amministratori di sistema possono sfruttarlo per gestire server o workstation in diverse versioni o distribuzioni, garantendo compatibilità e prestazioni. Distrobox consente inoltre di creare un ambiente modificabile su sistemi operativi totalmente o parzialmente immutabili come Endless OS, Fedora Silverblue, OpenSUSE MicroOS, ChromeOS o SteamOS3, consentendo di avere flessibilità in sistemi altrimenti statici. Inoltre, facilita la creazione di un’impostazione privilegiata a livello locale che elimina la necessità di sudo in scenari come i computer portatili forniti dall’azienda o in situazioni in cui la sicurezza è fondamentale. Inoltre, consente agli utenti di combinare la stabilità di sistemi come Debian Stable, Ubuntu LTS o RedHat con le caratteristiche all’avanguardia di ambienti con aggiornamenti cutting edge o progettati per lo sviluppo o il gioco. Il tutto è ulteriormente supportato dall’ampia disponibilità di immagini di distro curate per Docker/Podman, che consentono di gestire in modo efficiente più ambienti.
Permette di utilizzare qualsiasi distribuzione all’interno del terminale. Sfruttando tecnologie come Podman, Docker o Lilipod, crea container che si integrano strettamente con il sistema host
Facile da installare e usare da terminale
Iniziare con distrobox è semplice. Innanzitutto, assicuratevi che Docker, Podman o Lilipod siano installati sul vostro sistema. Quindi, installate distrobox attraverso il gestore di pacchetti della vostra distribuzione o direttamente dal suo repository GitHub. Creare un nuovo contenitore per la distribuzione Linux scelta è semplice come eseguire un comando, dopodiché ci si può immergere nell’ambiente containerizzato per svolgere il proprio lavoro.
Per esempio: distrobox create -n test
crea un nuovo ambiente containerizzato con il nome “test”. Il nome è un identificativo unico per ogni distrobox sul sistema.
distrobox create –name test –init –image debian:latest
–additional-packages “systemd libpam-systemd”
crea invece un distrobox chiamato “test” utilizzando come base l’ultima immagine di Debian. Il flag –init permette di avviare l’ambiente con un proprio sistema init, in questo caso Systemd, rendendolo simile a un container LXC (Linux Container). Qui si specificano inoltre dei pacchetti aggiuntivi da installare, come systemd e libpam-systemd, necessari per il corretto funzionamento di Systemd all’interno del container. Se volete aggiungere un distrobox con una specifica distribuzione diversa potete inoltre usare, per esempio per Ubuntu 20.04:
distrobox create -i ubuntu:20.04
Nel caso di quello chiamato “test”, dopo aver creato il vostro distrobox potete entrarci con:
distrobox enter test
ed eseguire comandi come se foste nella distribuzione ospitata dal container, in questo modo:
distrobox enter test — comando-da-eseguire
Punti di forza e aspetti a cui stare attenti
Uno dei punti di forza di questo strumento è l’efficienza in termini di risorse. I container utilizzano in genere meno risorse delle macchine virtuali, rendendo possibile l’esecuzione di più ambienti Linux su hardware meno recenti o su dispositivi con caratteristiche limitate. Inoltre, distrobox facilita la perfetta integrazione delle applicazioni tra diverse distribuzioni. Permette di installare praticamente qualsiasi software, anche se non è disponibile nei repository della vostra distribuzione, oppure se non è pacchettizzato per la vostra distro. Le applicazioni installate in un contenitore possono essere eseguite come se fossero presenti sul sistema host, compreso l’accesso alla vostra directory Home. Questa caratteristica semplifica la gestione dei file e migliora l’esperienza complessiva dell’utente, ma mette anche in risalto il fatto che, come spiega la documentazione, l’isolamento e il sandboxing non sono l’obiettivo principale del progetto, che al contrario mira a integrare strettamente il contenitore con l’host. I contenitori creati con distrobox avranno accesso completo alla vostra Home, ai vostri pen drive e ad altri componenti, quindi non aspettatevi che siano altamente isolati come un semplice contenitore Docker o Podman o un FlatPak. Se utilizzate Docker o Podman/Lilipod con il flag –root/-r , i contenitori verranno eseguiti come root, quindi root all’interno del contenitore rootful potrà intervenire sul sistema al di fuori del container stesso. In modalità rootful, vi verrà chiesto di impostare una password utente per garantire almeno che il contenitore non sia una porta senza password di accesso a root, ma se avete esigenze di sicurezza, usate Podman o Lilipod che funzionano in modalità rootless. Docker senza root non funziona ancora come previsto e gli sviluppatori assicurano che sarà proposto in futuro, quando sarà completo. In ogni caso, se vi piace sperimentare, vale la pena di provare distrobox!
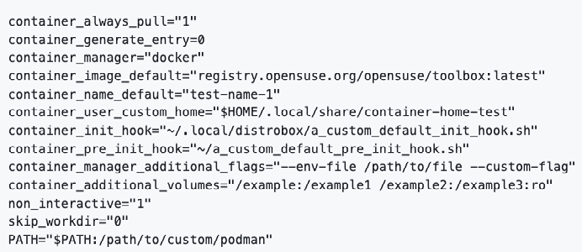
Potete personalizzare il file di configurazione per avere un controllo avanzato su come distrobox avvia e gestisce i container Linux, adattando l’ambiente ai vostri specifici bisogni e preferenze di sviluppo, testing o esplorazione di diverse distribuzioni

278 – Dal 10 luglio 2024!
-
-
New entry: Saluti (+ricerca arretrati)
Buongiorno a tutti! Ho avuto modo di apprezzarVi divers...
Di Pandy , 7 mesi fa
-
ciao a tutti sono nuovo sul sito.avrei bisogno di aiuto...
Di Eidan39 , 7 mesi fa
-
Ciao a tutti...! App per il trucco
Salve a tutti, sono un programmatore da 4 anni, ma mi c...
Di Mariana21 , 10 mesi fa
-







-

 News3 anni ago
News3 anni agoHacker Journal 278
-

 News7 anni ago
News7 anni agoAbbonati ad Hacker Journal!
-
 Articoli2 anni ago
Articoli2 anni agoParrot Security OS: Linux all’italiana- La distro superblindata
-

 Articoli3 anni ago
Articoli3 anni agoGuida: Come accedere al Dark Web in modo Anonimo
-

 Articoli6 anni ago
Articoli6 anni agoSuperare i firewall
-

 News4 anni ago
News4 anni agoLe migliori Hacker Girl di tutto il mondo
-

 Articoli5 anni ago
Articoli5 anni agoCome Scoprire password Wi-Fi con il nuovo attacco su WPA / WPA2
-

 News7 anni ago
News7 anni agoAccademia Hacker Journal